
Hao AI Lab Test AI Language Models on Phoenix Wright: Ace Attorney


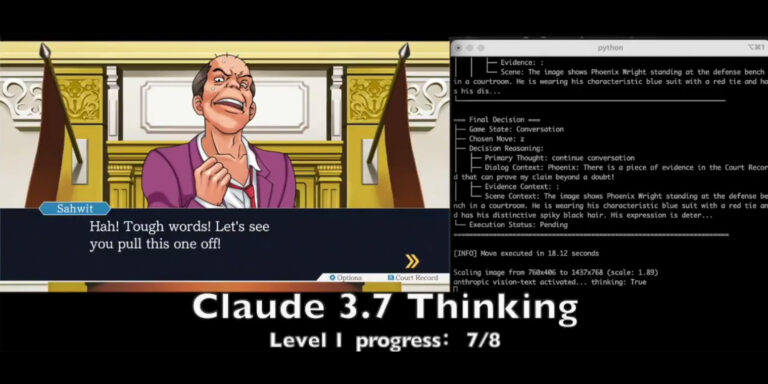
Various AI LLMs (Large Language Models) have been tested on video games before, but this time Hao AI Lab have used Ace Attorney as a test, and for an intriguing reason. The core idea is that if AI can understand and follow clues, it can come to the right conclusion in a case, which shows the LLM has learned from the experience.
In a recent X (Twitter) post, Hao AI Lab outlined its inspiration for this latest experiment. It involved a March 2023 talk by Ilya Sutskever, the co-founder of OpenAI, with Jensen Huang, the CEO of NVIDIA, and the implications of predictive text.
“When Ilya Sutskever once explained why next-word prediction leads to intelligence, he made a metaphor: if you can piece together the clues and deduce the criminal’s name on the last page, you have a real understanding of the story,” Hao AI Lab said on X.
“Inspired by that idea, we turned to Ace Attorney to test AI’s reasoning. It’s the perfect stage: the AI plays as a detective to collect clues, expose contradictions, and uncover the truth.”
Jump to:
Objection!
Phoenix Wright: Ace Attorney is a type of visual novel that revolves around complex court cases. It was first released in 2001 for the GameBoy Advance but has since been ported to other consoles, such as the Switch, and PC.
“In our setup, models are tested on the intense cross-examination stage. It must spot contradictions and present the correct evidence to challenge witness testimony. Each level grants 5 lives, allowing limited tolerance for mistakes.”

Hao AI Lab noted that it used O1, Gemini 2.5 Pro, Claude 3.7-thinking, and Llama-4 Maverick AI for this experiment. These are multimodal AI, meaning they can interpret any input, such as video, sound, and text, and convert them into suitable outputs. For example, if it’s shown an image of a cake, it can generate a suitable recipe to make that cake.
Hao AI Lab’s findings are based on three core principles the AI models had to follow: long-context reasoning, visual understanding, and strategic decision-making. However, while the Lab noted that O1 and Gemini 2.5 Pro performed the best, the overall game design proved a tough challenge.
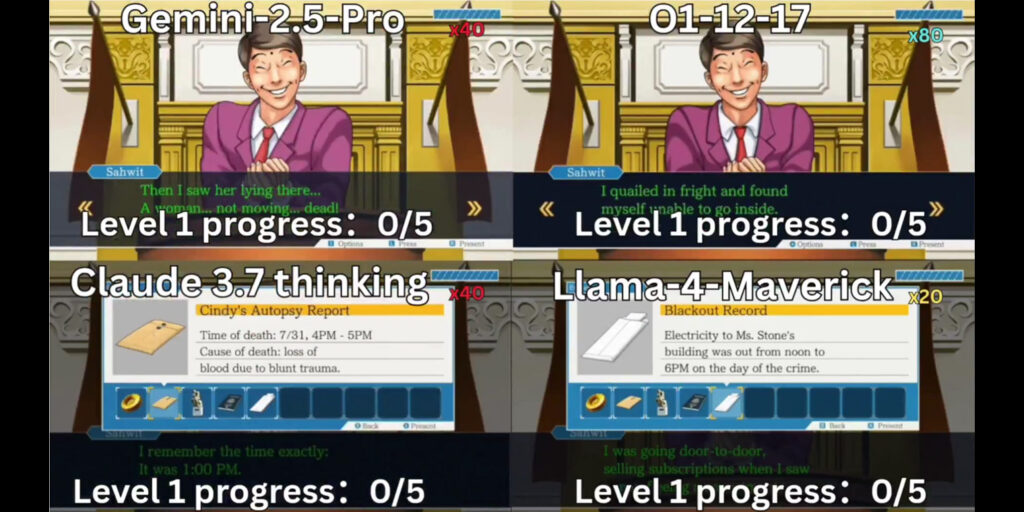
“Game design pushes AI beyond pure textual and visual tasks by requiring it to convert understanding into context-aware actions. It is harder to overfit because success here demands reasoning over context-aware action space – not just memorization.”
AI Benchmarks
Hao AI Lab is part of the University of California San Diego and its aim is to democratize various AI models. It does this primarily through open source code, but also by investigating how AI models work, including their energy consumption and related factors.
As part of its attempt to create a robust benchmark system, Hao AI Lab looks at things like how many API calls an AI makes when it’s working. An API call is, basically, the process of requesting and sending data between different programs. If an AI makes a lot of API calls, then its cost efficiency goes up. In short, the lower the amount of API calls, the better the energy use of the model.
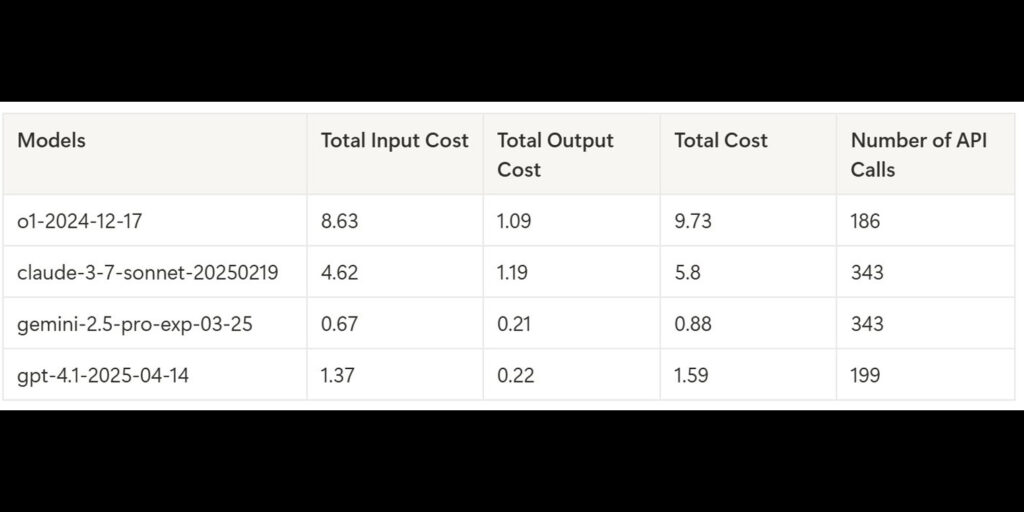
“In our table for models that passed Level 1, O1 made the fewest API calls but still had the highest cost. The call count reflects strategy, not reasoning strength, as models that dig deeper into testimony naturally trigger more requests,” Hao AI Lab said on X.
“Beyond Level 1, as conversations get longer, O1’s cost skyrockets. In Level 2, which is a really long case, O1 cost over $45.75, while Gemini 2.5 Pro handled it for $7.89. That’s a massive gap!”
Hao AI Lab previously tested LLMs on the original Super Mario and are behind Game Arena, a site that shows how AI does on other video games.















